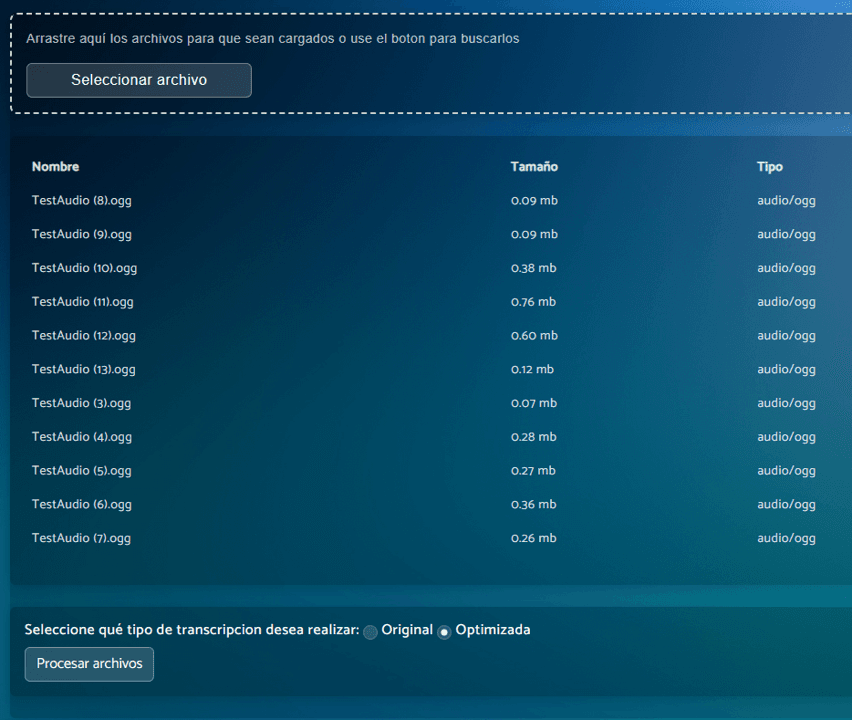
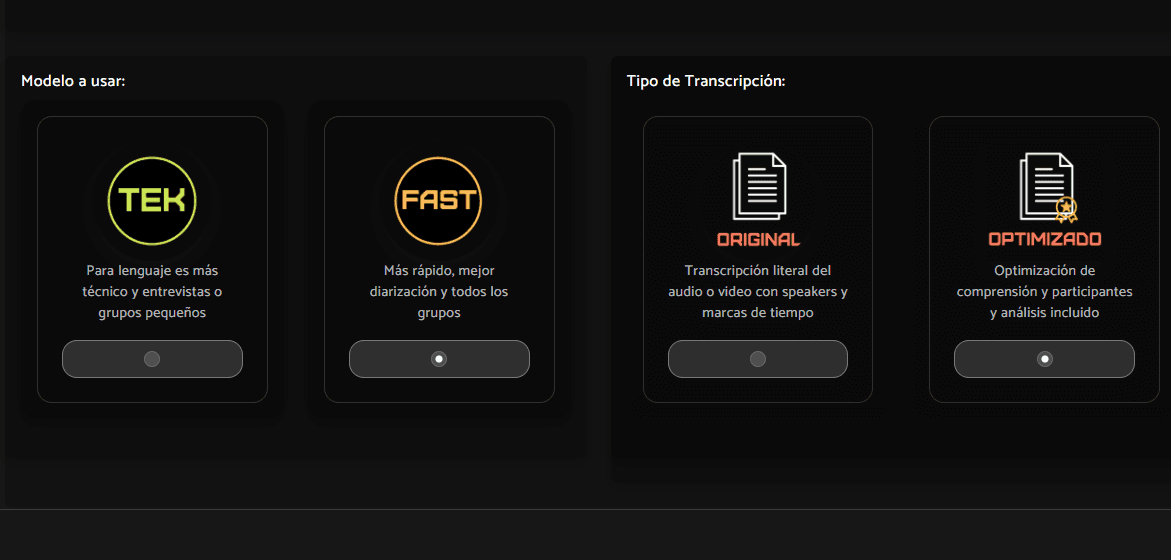
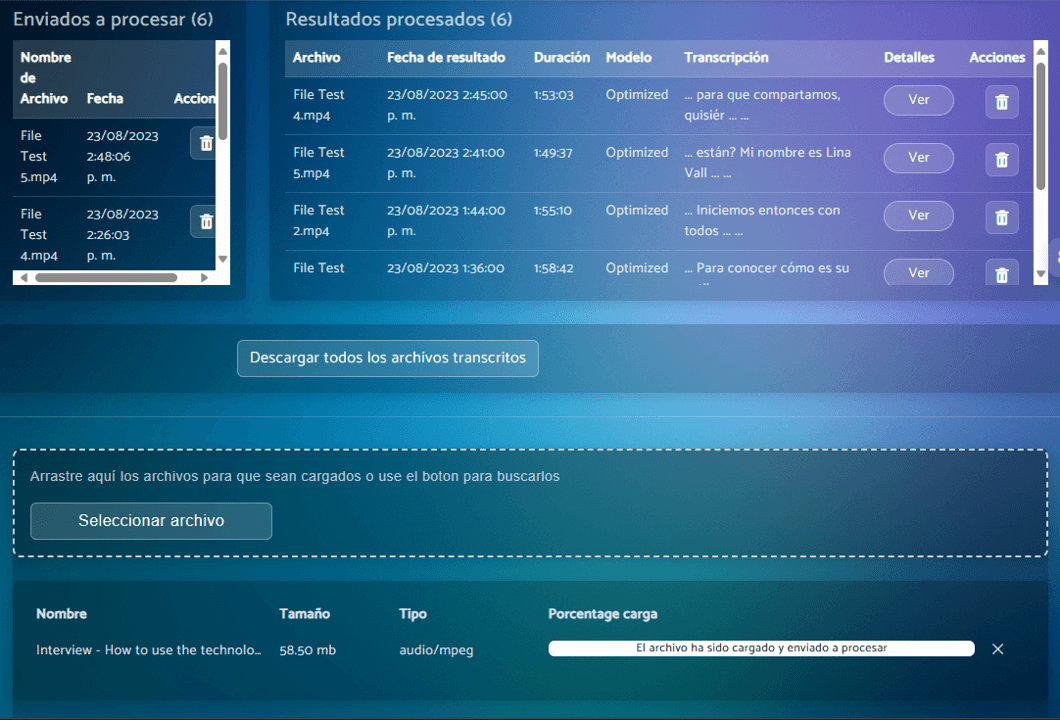
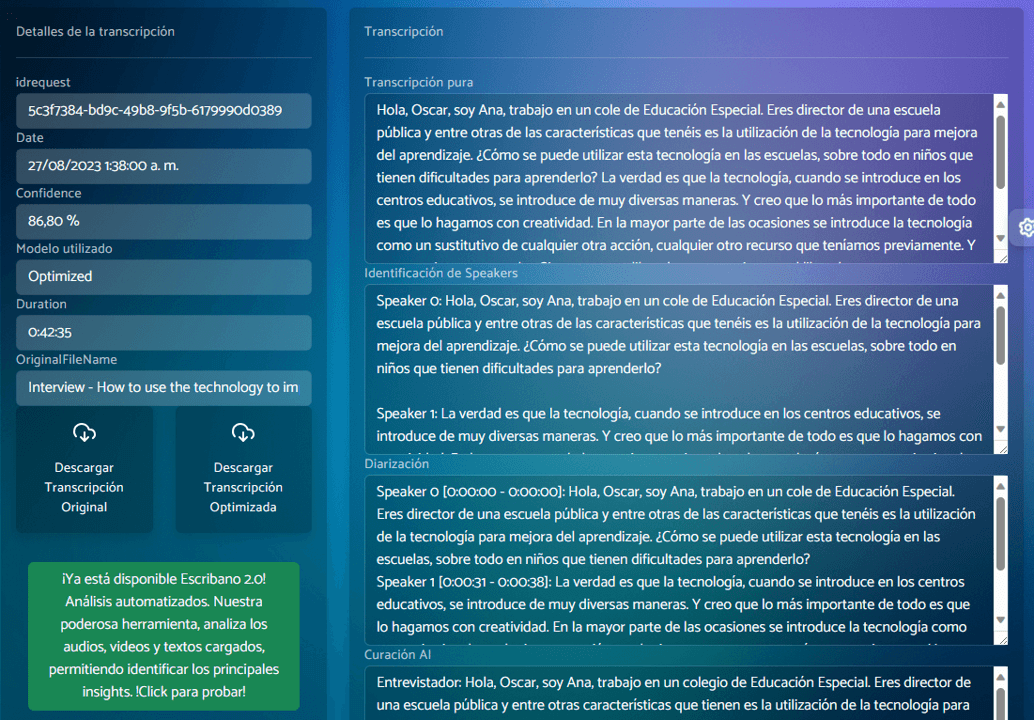
Results 100x Faster
No matter the number of videos or audios you send us, all will be processed in parallel, ensuring delivery within 24 hours or sometimes, even minutes.
Time SavingReduce Operational Workload
Cut down on operational work and human error while saving costs by 30% to 70% compared to traditional models.
Cost ReductionFacilitate Value Addition
Focus on what really matters—adding value by leveraging your team's expertise to the fullest.
Value Generation