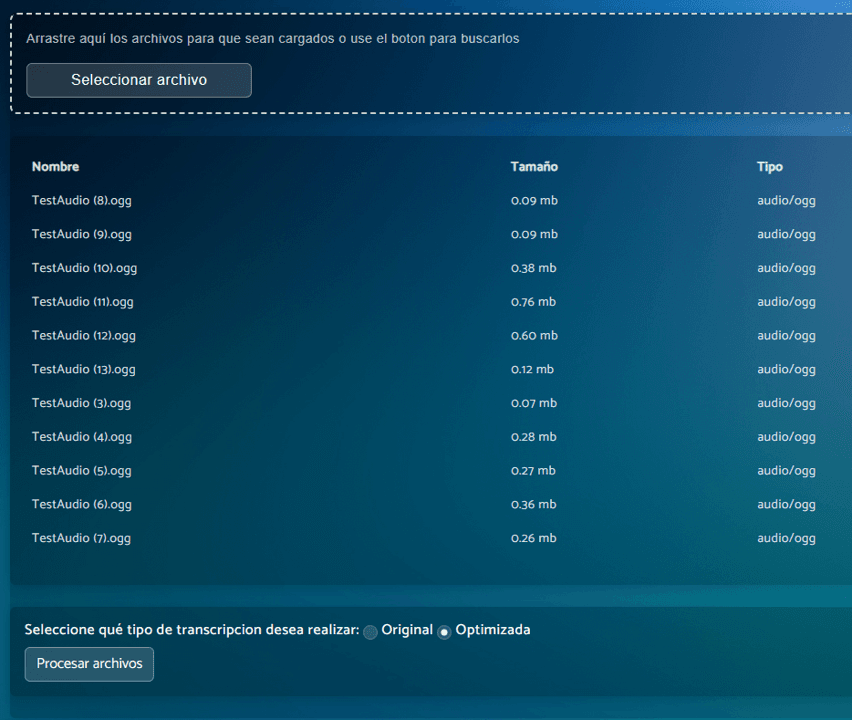
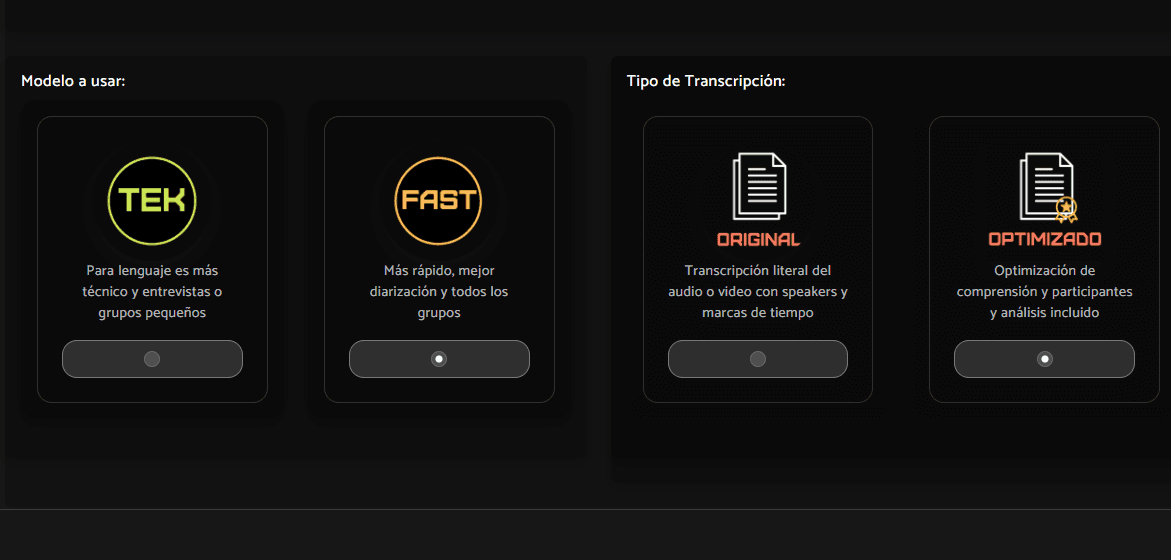
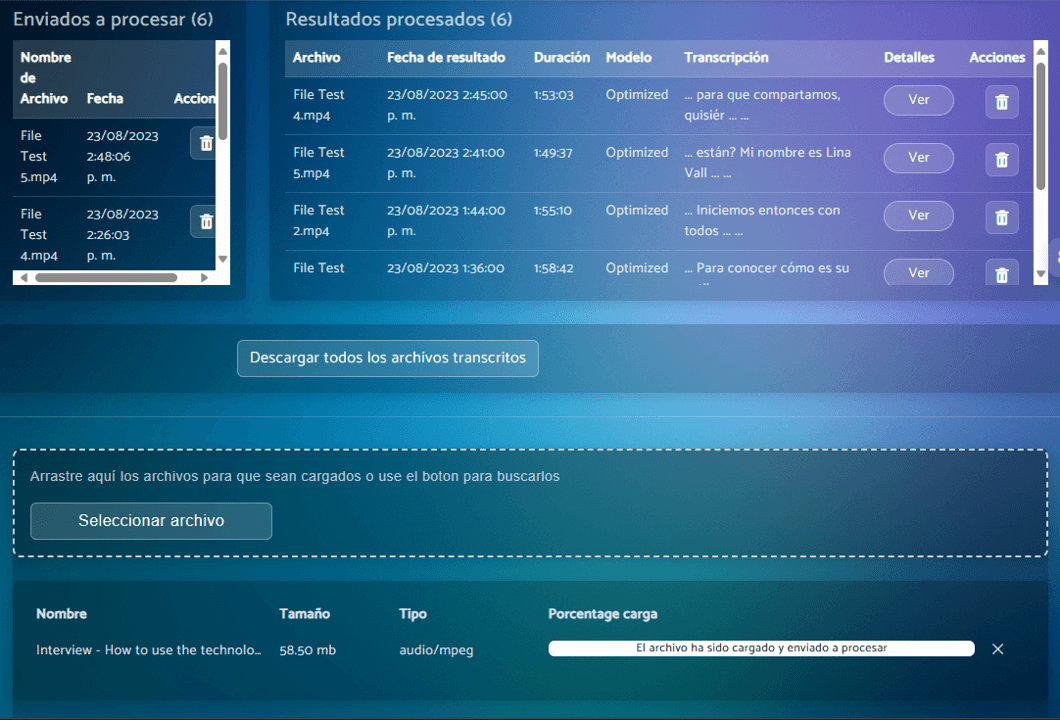
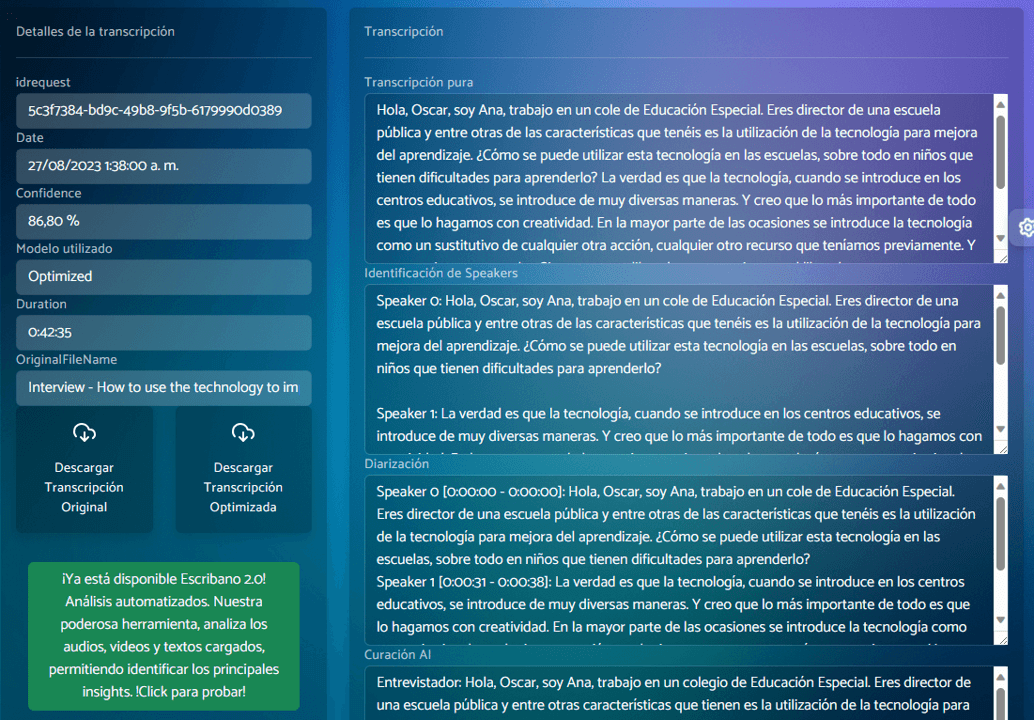
Resultados 100x más rápido
Sin importar la cantidad de videos o audios que nos envíes, todos serán procesados en paralelo garantizando la entrega en 24 horas o menos. A veces, incluso en minutos.
Ahorro de tiempoReduce la operatividad
Reduce el trabajo operativo y el margen de error humano al tiempo que ahorras en costos entre el 30% y el 70% versus el modelo tradicional
Reducción de costosFacilita el valor agregado
Enfócate en lo que realmente cuenta, agregar valor aprovechando al máximo el conocimiento de tu equipo
Generación de valor